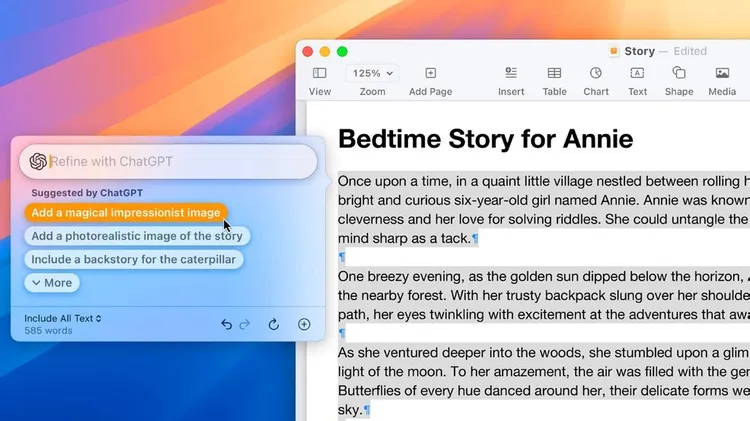
Voice cloning breakthrough will make AI assistants sound less
Chatbots that sound just like us
3 min read
This article is from...

Read this article and 8000+ more magazines and newspapers on Readly